Overview
Data Applications Lifecycle – Three Critical Phases
The lifecycle of data applications involves three key phases:
- Infrastructure Upgrades: Upgrading core components such as Spark, Iceberg, Python, or internal infrastructure.
- Migrations: Transitioning from Yarn to Kubernetes, on-premises to cloud, Databricks to EMR, etc.
- Version Releases: Deploying new application versions and bug fixes.
Infrastructure upgrades and migrations require coordinated efforts between platform teams and application owners. While platform teams ensure the new environment is supported, application owners must update their builds accordingly and conduct thorough validation:
- Run side-by-side executions of both versions on identical input data.
- Monitor and compare data and performance metrics to ensure parity.
- If discrepancies arise, perform a Root Cause Analysis (RCA).
These validation steps make upgrades and migrations resource-intensive and manual, often leading organizations to postpone them—impacting platform performance and increasing costs.
Similarly, ongoing version releases and fixes can introduce unexpected performance regressions or business-impacting issues. However, these are rarely pre-tested to identify potential risks in advance.
Definity automates these validation stages (1-3), enabling seamless, low-impact migrations and upgrades.
Definity CI Workflow
Step 1: Automating Data Application Staging
Objective: Run any pipeline consisting of multiple Spark jobs, reading production input data while redirecting all intermediate and output writes to a staging path.
Required Definity Agent Configuration:
| Name | Description |
|---|---|
spark.definity.output.table.suffix | Suffix appended to all output table names. |
spark.definity.output.database.suffix | Suffix added to output database names. |
spark.definity.output.database.baseLocation | Base location for all generated output databases. |
Step 2: Comparative Analysis Between Versions
Once both runs are generated using Definity's agent configuration, a comparative analysis report can be created:
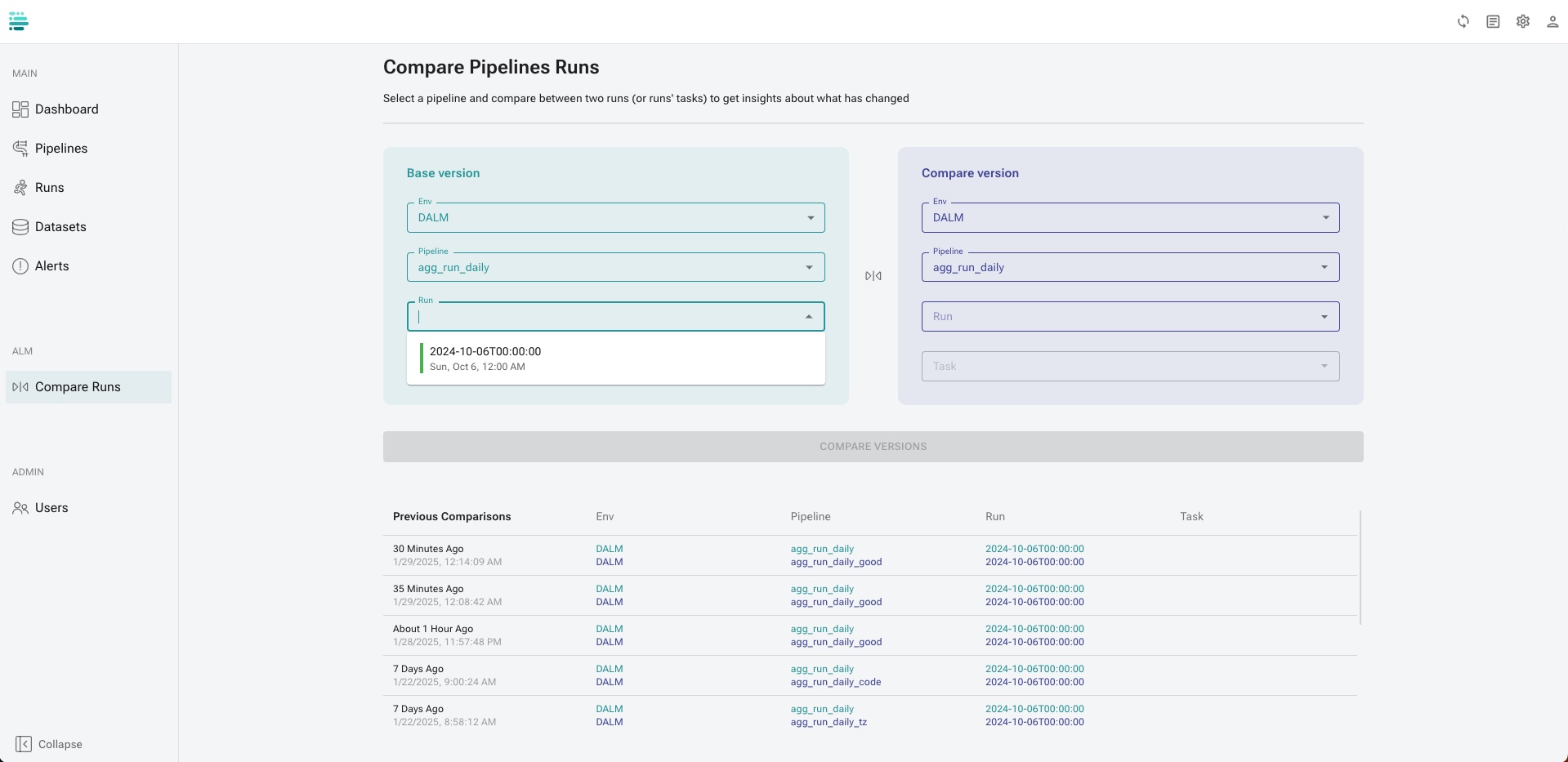
To ensure accuracy, select the same pipeline version and the same point-in-time (PIT) snapshot to compare equivalent datasets:
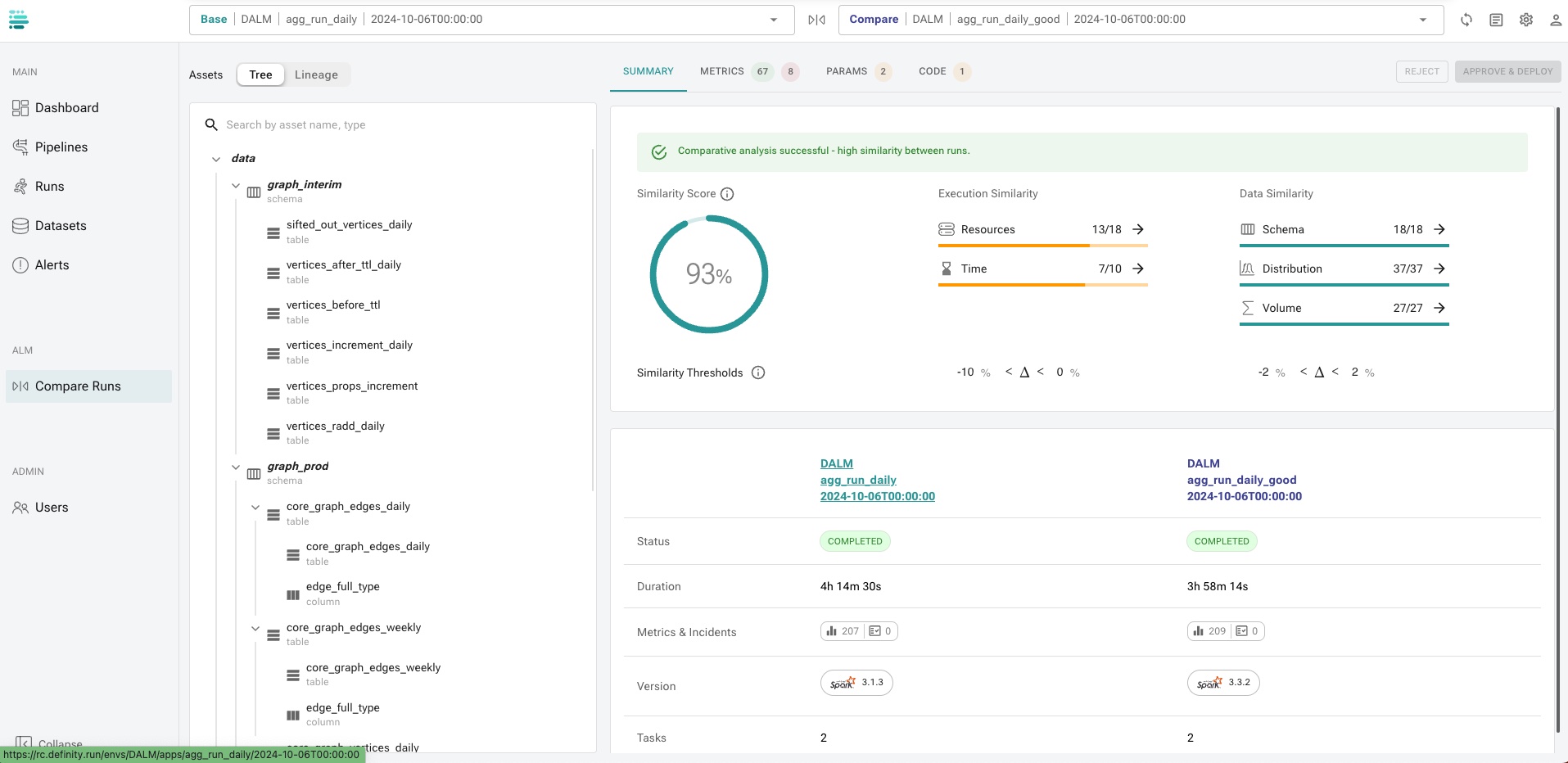
Adjust threshold values to define acceptable data and performance metric deviations.
Step 3: Root Cause Analysis (RCA)
If discrepancies exceed defined thresholds, drill down to identify the root cause of the changes:
A. Determine whether discrepancies stem from data changes or technical execution issues.
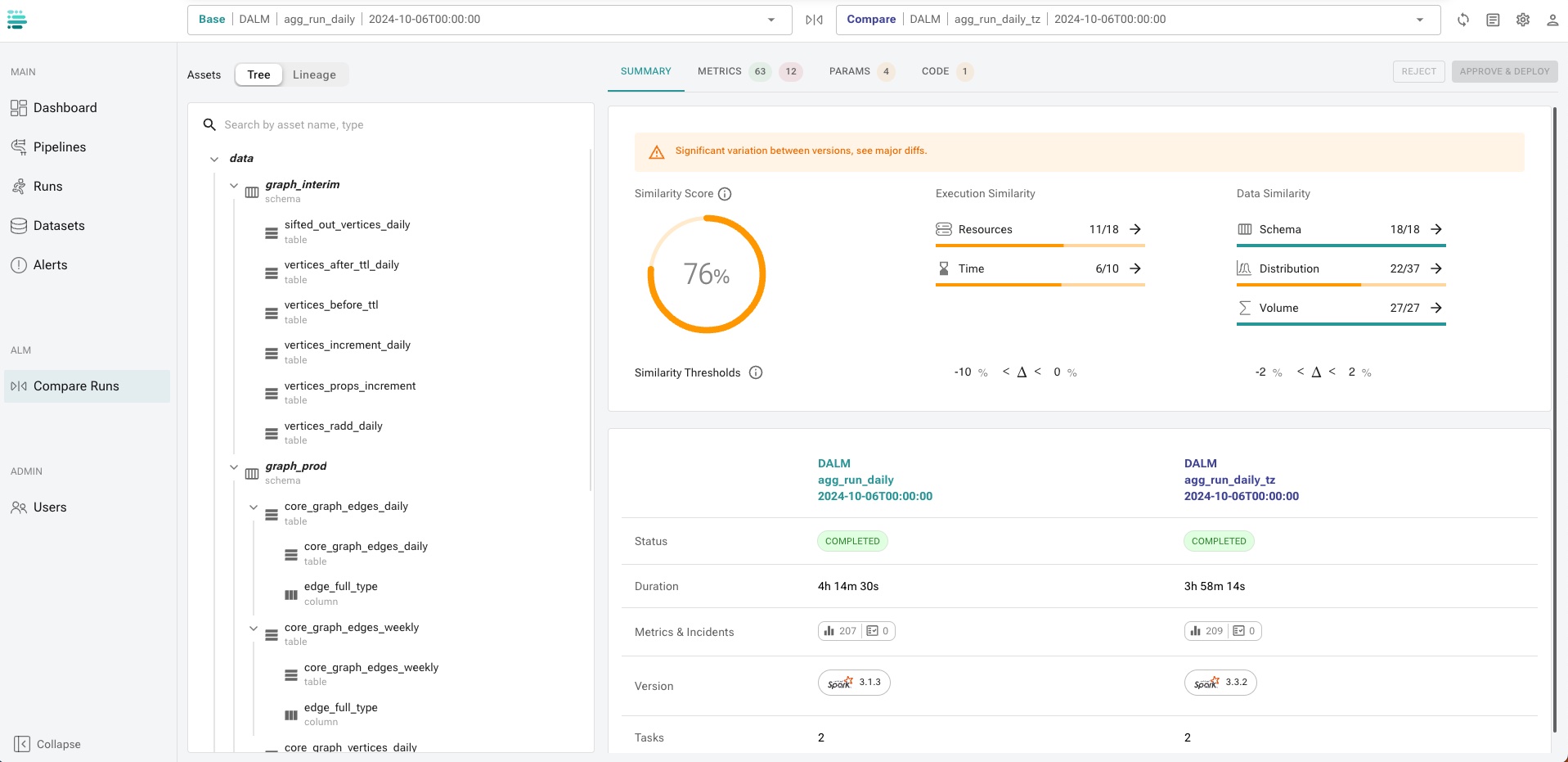
B. Analyze affected metrics collected by Definity to identify out-of-bound shifts.
C. Use the lineage view to pinpoint where in the pipeline the issue originated.
D. Quickly diagnose environment or code changes contributing to unexpected shifts.
By automating these steps, Definity streamlines migrations, upgrades, and release validations—reducing manual effort while minimizing performance risks.