Health Overview
Overview
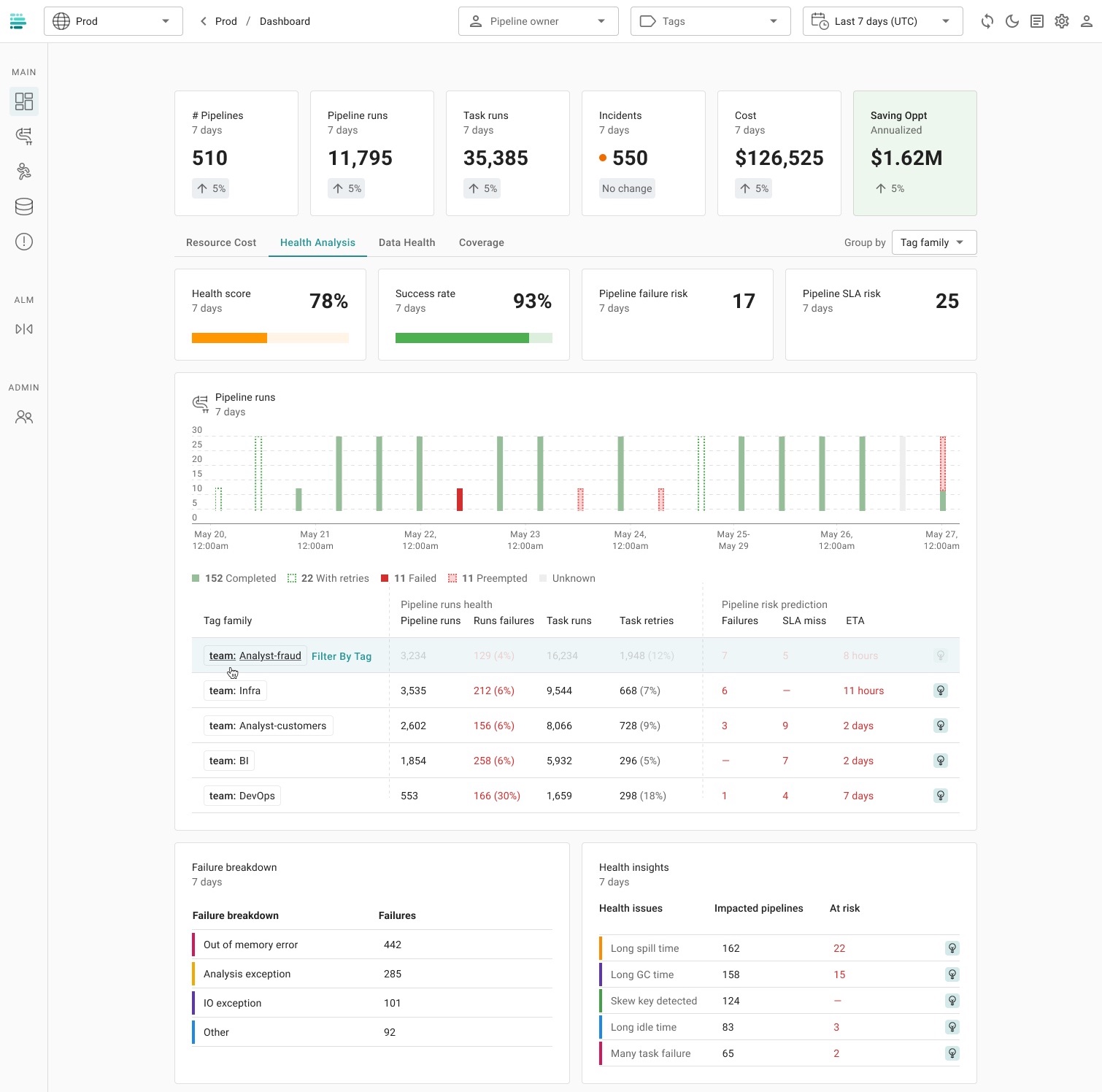
Definity provides a comprehensive Health Monitoring system for data pipelines, ensuring optimized performance, reliability, and efficiency. By tracking critical pipeline metrics and leveraging automatic insights, Definity proactively identifies risks and provides actionable recommendations.
Pipeline Health
Definity continuously monitors key aspects of data pipeline health, enabling engineers to detect issues early and maintain smooth operations:
- Pipeline Executions & Success Rate – Monitors the number of successful executions versus failures, helping identify trends over time.
- Task Failures & Retries – Tracks failures within each pipeline to assess reliability and stability.
- SLA Compliance & Execution Duration – Measures adherence to SLAs and identifies performance bottlenecks at both pipeline and task levels.
Advantages of Definity’s Health Monitoring
- Real-Time Visibility: Gain instant insights into the operational health of your Spark jobs.
- Proactive Issue Detection: Identify potential bottlenecks and failures before they impact production.
- Optimized Performance: Reduce execution time and improve resource utilization.
- Automated Insights & Recommendations: Receive AI-driven suggestions to fix performance issues and enhance efficiency.
Risk Prediction - TODO consider remove
Definity predicts two key types of risks to prevent failures and ensure SLA compliance:
-
Failure Risk Prediction – Based on historical trends and real-time telemetry, Definity predicts pipeline failures using factors such as:
- Execution time variations
- Memory consumption patterns
- Garbage Collection (GC) impact
- Data spilling and shuffle inefficiencies
- CPU & Disk utilization
-
SLA Miss Risk Prediction – Analyzes trends in execution times and resource contention to detect jobs at risk of exceeding SLA thresholds, allowing for proactive mitigation.
Health Insights & Automatic Fixes
Definity provides deep health insights with automated recommendations to optimize performance and reduce failures:
- Disk Spill Impact & Fixes – Detects high disk spill occurrences and suggests memory tuning strategies.
- Garbage Collection (GC) Analysis – Identifies excessive GC overhead and recommends optimizations such as heap size tuning.
- Skew Detection & Skew Key Analysis – Highlights data skew issues and suggests partitioning improvements.
- Job Idle Time Analysis – Identifies periods of inactivity within Spark jobs and provides fixes to minimize resource wastage.
- Task Failures & Retries – Analyzes failure patterns and suggests configuration optimizations to reduce retry rates.
Why Automatic Insights Matter
- Reduced Debugging Time – Engineers spend less time troubleshooting and more time on innovation.
- Optimized Resource Utilization – Minimize wasted computation and storage.
- Improved SLA Compliance – Detect and fix performance degradation before it impacts SLAs.
Failure Breakdown & Common Errors
Definity categorizes and analyzes common Spark job failures to provide targeted solutions for example:
- Out of Memory (OOM) Errors – Detects memory leaks and suggests tuning executor and driver memory settings.
- Analysis Exceptions – Identifies schema mismatches and missing dependencies that cause execution failures.
- I/O Exceptions – Highlights data source issues such as read/write failures and recommends mitigation strategies.
Definity Main Health Dashboard